TL;DR: At XRPL Commons, we’ve been experimenting with local AI infrastructure for development workflows: coding assistants, document drafting, agent systems, and internal tooling. We got a 30B-parameter LLM running at 51–54 tokens/sec on the NVIDIA DGX Spark by combining Mixture-of-Experts models, FP8 quantization, and a community Docker image that fixes Blackwell compatibility issues. Full setup below, brought to you by our CTO.
Why We Wanted Local LLMs
At XRPL Commons, we’ve been experimenting with local AI infrastructure for development workflows: coding assistants, document drafting, agent systems, and internal tooling.
Our requirements were simple:
- Fast enough for interactive use
- Private enough to run on-premise
- Replicable across multiple machines
The DGX Spark looked like an interesting candidate. But achieving good performance requires understanding its real constraint.
The Hardware
The DGX Spark packs significant compute into a desktop system:
- NVIDIA GB10 Blackwell GPU (SM 12.1)
- 128 GB unified LPDDR5X memory
- 273 GB/s memory bandwidth
- ARM Grace CPU (20 cores: 10 Cortex-X925 + 10 Cortex-A725)
- 4 TB NVMe M.2 (~3.7 TB usable)
- DGX OS (Ubuntu 24.04)
The standout feature is the 128 GB unified memory, which allows very large models to run locally.
But the critical limitation is memory bandwidth.
The Bandwidth Wall
LLM inference is primarily memory-bandwidth bound.
During autoregressive decoding, each token requires reading the active model weights from memory. With 273 GB/s bandwidth, the limits become clear:
Model

Our first runs matched this almost exactly:
- Qwen3-32B (bf16): 3.7 tok/s
- Qwen3-8B (bf16): 13.1 tok/s
Large models fit comfortably in memory, but generate tokens slowly.
The MoE Breakthrough
The solution is Mixture-of-Experts (MoE) models.
Instead of activating the entire network, MoE models route each token through a subset of experts.
Example:
Qwen3-30B-A3B
- ~30.5B total parameters
- ~3.3B active parameters per token
This dramatically changes the bandwidth math:
Model

In practice, routing overhead, KV-cache reads, and software stack inefficiencies reduce throughput. Real systems typically achieve 50–70% of theoretical bandwidth limits.
The Blackwell Software Problem
The DGX Spark’s Blackwell GPU (SM 12.1) is new enough that much of the software stack is still catching up.
Issues we encountered:
- FlashAttention 2 crashes
- vLLM MoE kernels missing SM 12.1
- PyTorch officially supports only SM 12.0
- CUDA graphs disabled in standard builds
We initially built vLLM from source, patching build scripts and dependencies.
It worked, but required --enforce-eager mode (no CUDA graphs), which capped throughput at about 30 tok/s.
The Avarok Docker Image
A community project solved most of these issues.
The Avarok dgx-vllm Docker image includes:
- Patched vLLM v0.16.0rc2
- SM 12.1 Blackwell support
- Custom CUTLASS kernels
- Software fallback for missing NVFP4 instructions
- Working FlashAttention and CUDA graphs
Instead of hours compiling from source, deployment becomes a single Docker command.
Results
Model
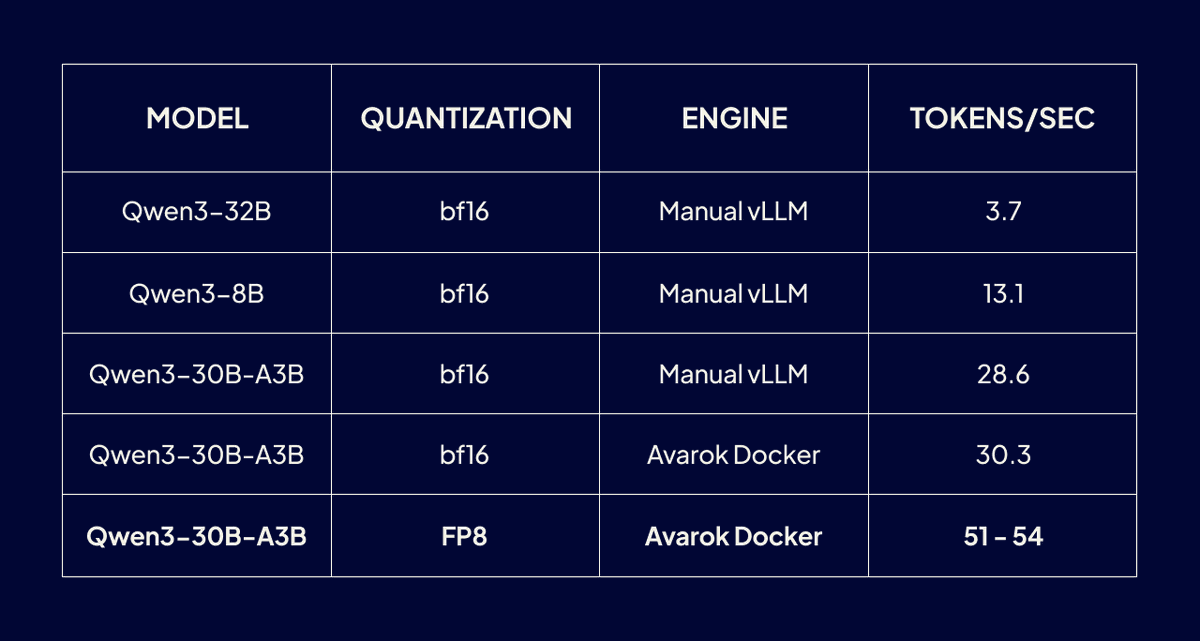
The winning combination:
MoE architecture + FP8 quantization + CUDA graphs via Avarok Docker
The FP8 model uses about 110 GB of GPU memory, leaving little headroom but delivering excellent throughput.
Final Setup
Deployment is straightforward:
shell
docker pull avarok/dgx-vllm-nvfp4-kernel:v22
docker run -d \
--name vllm \
--gpus all \
--shm-size=16g \
--restart unless-stopped \
-p 8000:8888 \
-v /home/$USER/.cache/huggingface:/root/.cache/huggingface \
-e MODEL=Qwen/Qwen3-30B-A3B-Instruct-2507-FP8 \
-e PORT=8888 \
-e GPU_MEMORY_UTIL=0.85 \
-e MAX_MODEL_LEN=32768 \
avarok/dgx-vllm-nvfp4-kernel:v22 serve
First startup takes 10–20 minutes (model download and CUDA graph capture). After that, the container auto-starts and exposes an OpenAI-compatible API:
http://localhost:8000/v1
Lessons Learned
1. Understand the bottleneck
On DGX Spark, memory bandwidth determines performance.
2. MoE models are ideal for bandwidth-limited systems
They dramatically reduce active weights per token.
3. FP8 quantization is a free win
Throughput nearly doubled from 30 → 51 tok/s.
4. Avoid building from source if possible
Community builds often include critical patches ahead of official releases.
5. Stop competing inference servers first
One Spark OOM-killed during installation because Ollama was using ~100 GB of memory.
6. Kernel updates can break NVIDIA drivers
If nvidia-smi fails after reboot:
shell
sudo apt install linux-modules-nvidia-580-open-$(uname -r)
Next Experiments
One promising direction is experimenting with reasoning-optimized models. A recent example is Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled (“Qwopus”), which distills structured reasoning from Claude 4.6 Opus into a Qwen3.5 base model.
While it is a dense model and therefore likely slower than our current MoE setup on the DGX Spark, it may offer stronger step-by-step reasoning for coding, math, and agent workflows.
Testing it is simple—swap the model in the same container:
shell
-e MODEL=Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
We plan to benchmark reasoning quality vs throughput alongside the current MoE setup.
References
NVIDIA DGX Spark
https://www.nvidia.com/en-us/data-center/dgx-spark/
Avarok dgx-vllm Docker project
https://github.com/avarok-ai/dgx-vllm
vLLM documentation
https://docs.vllm.ai
Qwen3-30B-A3B FP8 model
https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507-FP8
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
https://huggingface.co/Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
Let us know what you’re building.